LLM Fundamentals — Hallucinations in LLMs 101 [Part I]
Types of Hallucinations in LLMs


Def: A hallucination is a perception in the absence of an external stimulus that has a compelling sense of reality (Ref: Wiki).
In simple terms, a hallucination is an unreal perception that feels real.
For human beings — Hallucination traces its roots in the fields of pathology and psychology. It is defined as a set of experiences where a person perceives something that isn’t actually present. In human beings, hallucinations can affect any of the senses, including:
Auditory hallucinations: Hearing sounds, voices, or noises that aren’t there
Visual hallucinations: Seeing things that aren’t actually present, such as objects or people
Olfactory hallucinations: Smelling odours that have no external source
Gustatory hallucinations: Tasting flavours that aren’t actually present.

Hallucinations can be caused by a range of factors, including mental health conditions, neurological disorders, substance abuse, or extreme stress and fatigue.
Hallucinations in LLM
The emergence of LLMs and their wide-scale adoption in recent years has opened innumerable opportunities to integrate AI/ML seamlessly into technology products across domains. However, while doing so it has become imperative to understand Hallucinations in LLMs and the impact it has on the adoption of LLMs in live technology platforms wrt the reliability of the output that the LLM systems generate.
Within the realm of (Natural Language Processing (NLP), hallucination is typically referred to as a phenomenon in which the generated content appears nonsensical or unfaithful to the provided source content (Filippova, 2020; Maynez et al., 2020).

LLM Hallucination — Ref #2 (A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions Huang et al.)
Categorization of Hallucination in LLMs
Initially, LLM Hallucinations were categorized into 2 types:
Intrinsic Hallucinations: The output generated by the LLM that contradicts the source content. For instance, in the abstractive summarization in the below example, the generated summary “The first Ebola vaccine was approved in 2021” contradicts the source content “The first vaccine for Ebola was approved by the FDA in 2019.”
Extrinsic Hallucinations: The output generated by the LLM cannot be verified from the source content (i.e., output that can neither be supported nor contradicted by the source). For example, in the abstractive summarization task in the below example, the information “China has already started clinical trials of the COVID-19 vaccine.” is not mentioned in the source. We can neither find evidence for the generated output from the source nor assert that it is wrong. Notably, extrinsic hallucination is not always erroneous because it could be from factually correct external information. Such factual hallucination can be helpful because it recalls additional background knowledge to improve the informativeness of the generated text. However, in most of the literature, extrinsic hallucination is still treated with caution because its unverifiable aspect of this additional information increases the risk from a factual safety perspective.

Abstractive Summarization — Ref #1 (Survey of Hallucination in Natural Language Generation — Ji et al.)
In recent times, the LLMs emphasize user-centric interactions, and their hallucinations appear at factual levels. Taking this into consideration Huang et al. in their paper “A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions” introduced a more granular hallucination taxonomy as follows:

Categories of Hallucinations
Factual Hallucination
Existing LLMs frequently manifest tendencies to produce results that are either inconsistent with real-world facts or are most likely misleading. This poses a challenge to the trustworthiness of artificial intelligence. In such a context, such factual errors are classified as factuality hallucinations.
Depending on whether the generated factual content can be verified against a reliable source, they can be further divided into two primary types:
Factual Inconsistency — It refers to situations where the LLM’s output contains facts that can be grounded in real-world information, but present contradictions. This type of hallucination occurs most frequently and arises from diverse sources, encompassing the LLM’s capture, storage, and expression of factual knowledge. As shown in the below example, when inquired about “the first person to land on the Moon”, the model erroneously generated “Yuri Gagarin”, which contradicts the real-world fact.
Factual Fabrication — Here the LLM’s output contains facts that are unverifiable against established real-world knowledge. As demonstrated in the below example, while “the origins of unicorns” traditionally lack empirical grounding, the model fabricated a plausible historical origin for unicorns.

Types of Factual Hallucinations — Ref #2 (A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions Huang et al.)
Faithfulness Hallucination
LLMs by default are trained to align with the instructions given by the user. As the use of LLMs shifts towards more user-centric applications, ensuring their consistency with user-provided instructions and contextual information becomes crucial. Moreover, LLM’s faithfulness is also reflected in the logical consistency of its generated content. From this perspective, Huang et al. categorize three subtypes of faithfulness hallucinations:
Instruction inconsistency — In this type of hallucination the LLM’s outputs deviate from a user’s directive. While some deviations might serve safety guidelines, the inconsistencies here signify unintentional misalignment with non-malicious user instructions. As shown in the below example, the user’s actual intention is translation, However, the LLM erroneously deviated from the user’s instruction and performed a question-answering task instead.
Context inconsistency — These are the hallucinations where the LLM’s output is not consistent/faithful with the user’s provided contextual information. As shown in the below example, the user mentioned the Nile’s source being in the Great Lakes region of central Africa, yet the LLM’s response contradicted the context.
Logical inconsistency — In this type of hallucination the LLM outputs reveal internal logical contradictions, especially observed in their reasoning tasks. As a result, inconsistencies appear both among the reasoning steps themselves and between the steps and the final answer. As shown in the below example, while the reasoning step of dividing both sides of the equation by 2 is correct, the final answer of x=4 is inconsistent with the reasoning chain, leading to an incorrect result.
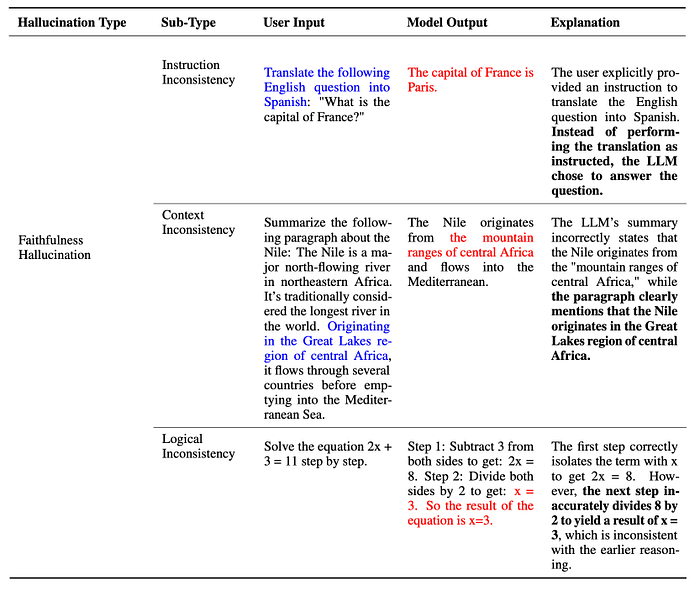
Types of Faithfulness Hallucinations — Ref #2 (A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions Huang et al.)
References
Survey of Hallucination in Natural Language Generation — Ji, Ziwei and Lee, Nayeon and Frieske, Rita and Yu, Tiezheng and Su, Dan and Xu, Yan and Ishii, Etsuko and Bang, Ye Jin and Madotto, Andrea and Fung, Pascale
A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions — Lei Huang and Weijiang Yu and Weitao Ma and Weihong Zhong and Zhangyin Feng and Haotian Wang and Qianglong Chen and Weihua Peng and Xiaocheng Feng and Bing Qin and Ting Liu
Note: Significant content of this tech blog has strong references from the above 2 papers.
In our next blog, we will dive deep into the key aspects contributing to hallucinations in LLMs. Stay tuned 💡
Follow us : NonStop io Technologies